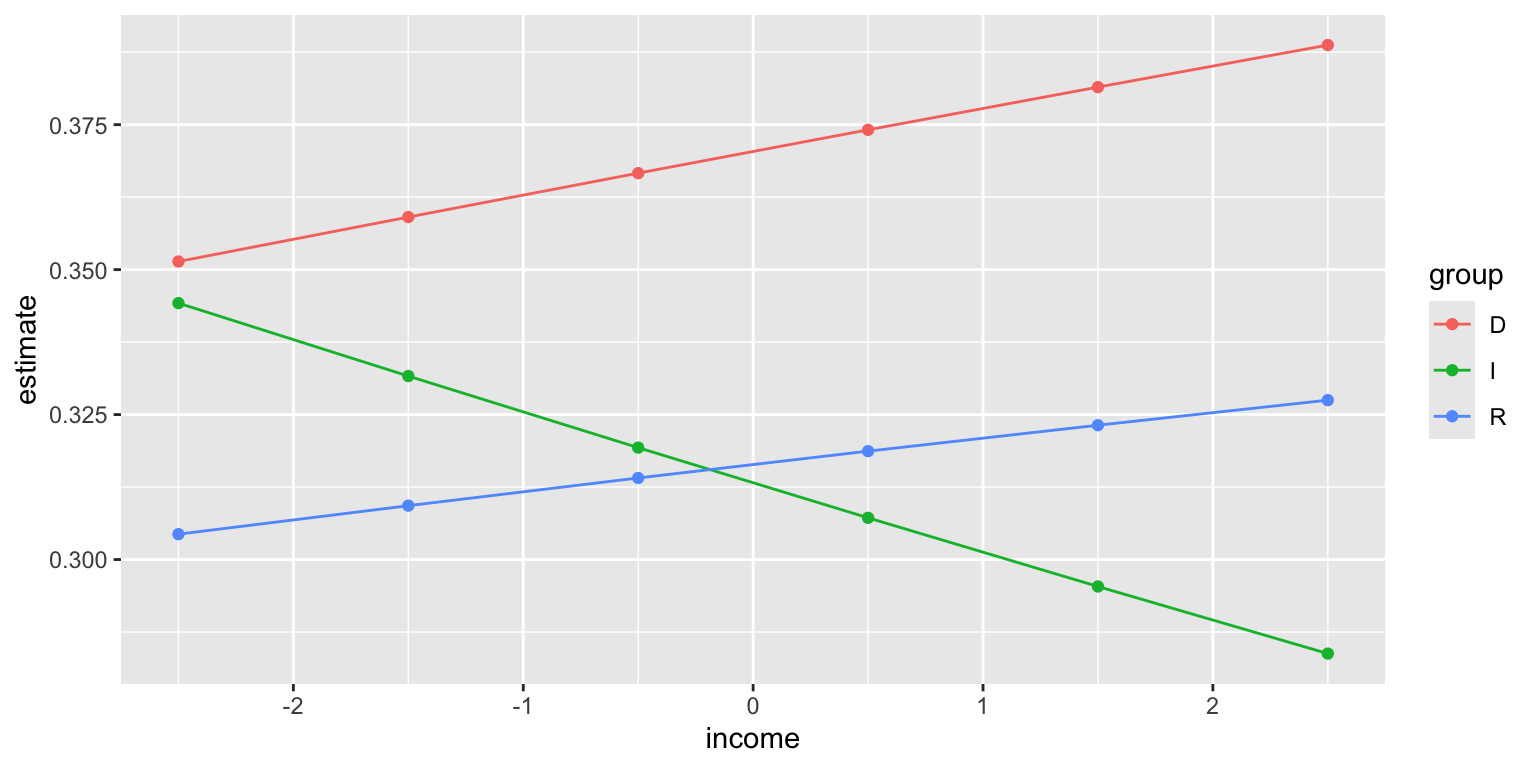
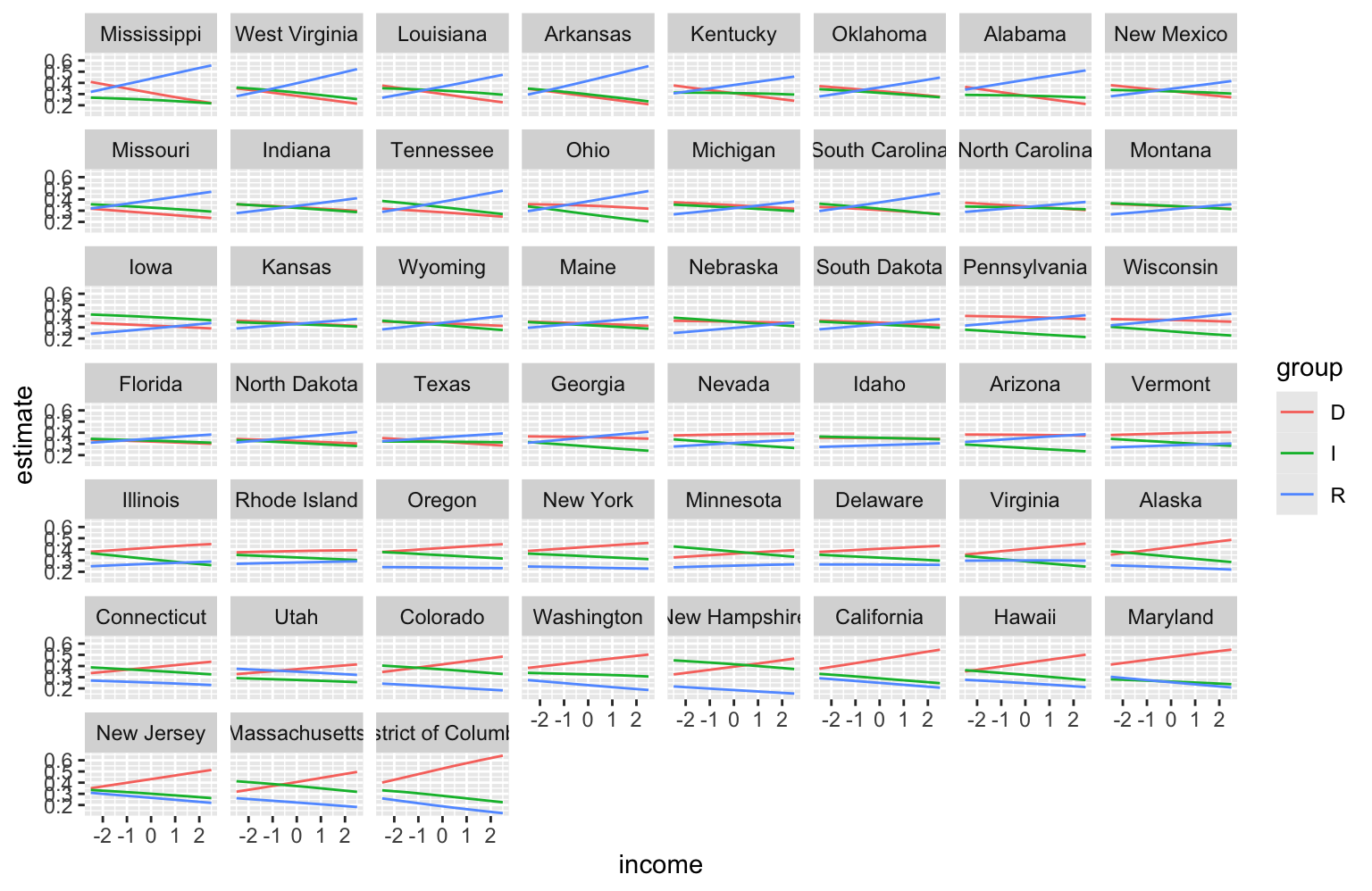
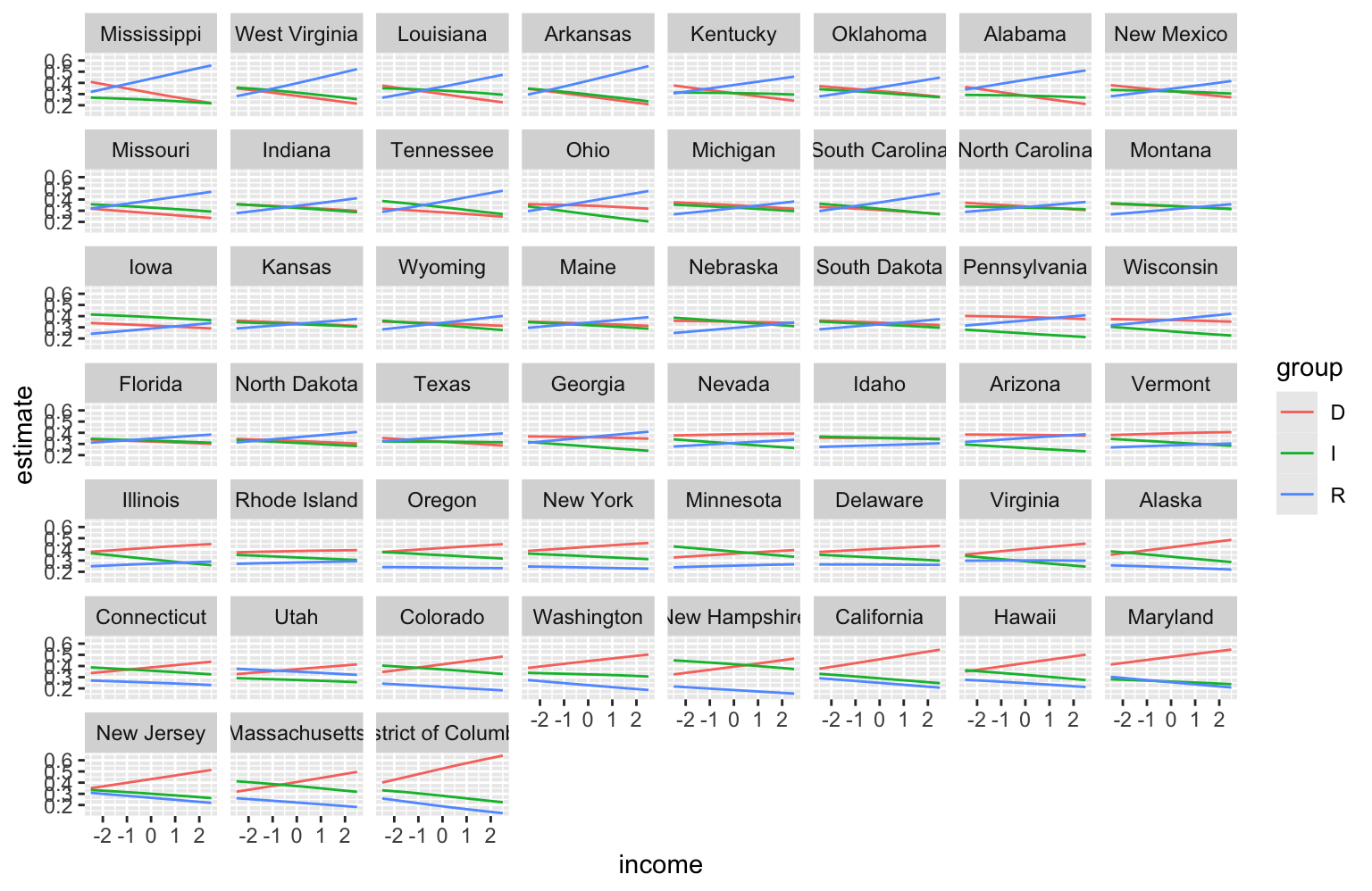
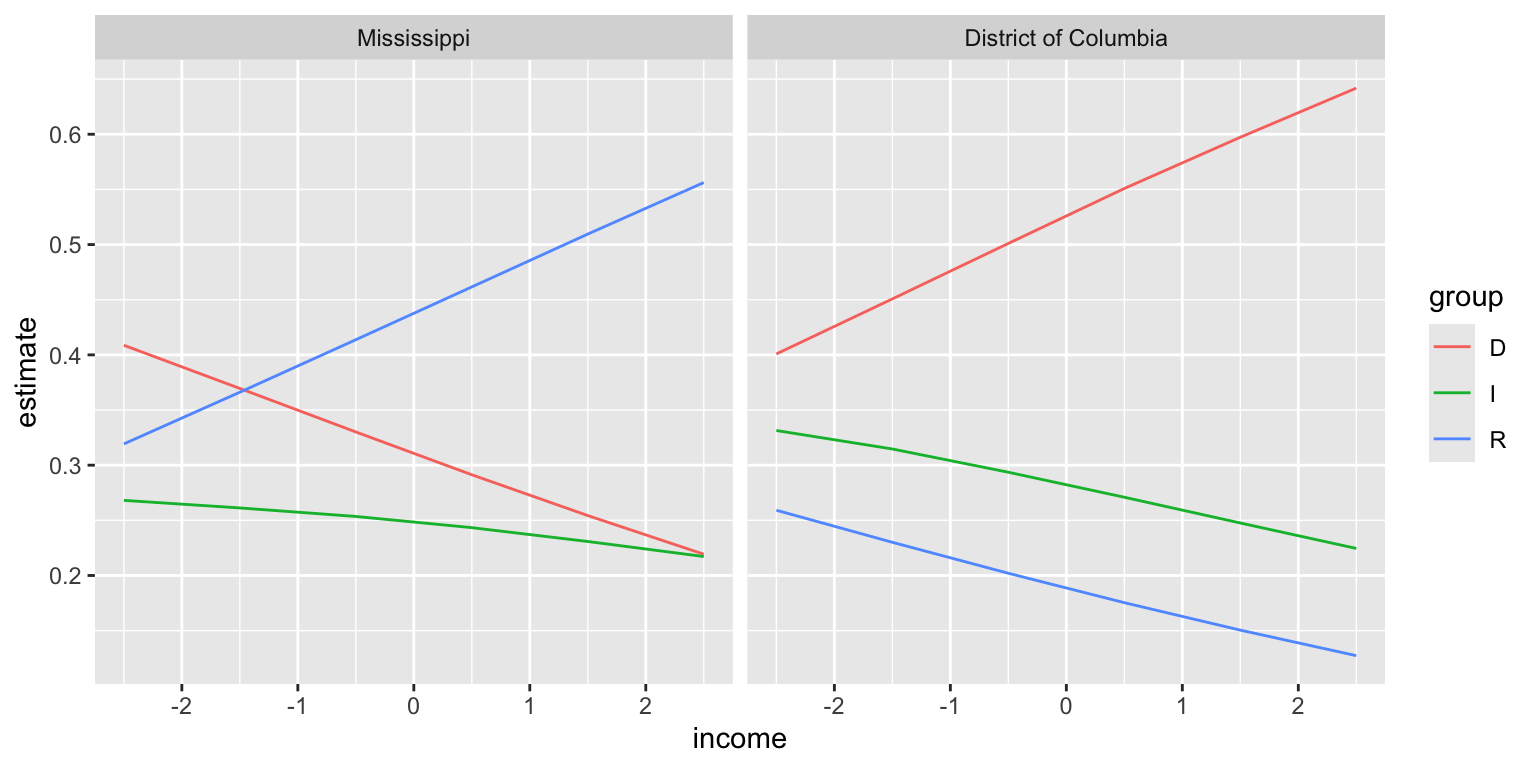
viewof z1 = Inputs.range([-5, 5], {step: 0.1, value: 1, label: "z1"});
viewof z2 = Inputs.range([-5, 5], {step: 0.1, value: 0.5, label: "z2"});
viewof z3 = Inputs.range([-5, 5], {step: 0.1, value: -0.5,label: "z3"});
viewof z4 = Inputs.range([-5, 5], {step: 0.1, value: -1, label: "z4"});
// Softmax pieces
labels = ["Pr(A)","Pr(B)","Pr(C)","Pr(D)"];
zs = [z1, z2, z3, z4];
exps = zs.map(Math.exp);
sumexp = exps.reduce((a, b) => a + b, 0);
ps = exps.map(e => e / sumexp);
// Data for stacked bar (one row, four segments)
data = ps.map((p, i) => ({ label: labels[i], value: p, row: "softmax" }));
// === Two-column layout: sliders (left) + live table (right) ===
{
const container = html`<div style="
display:flex;
gap:24px;
align-items:flex-start;
padding-top:8px;
"></div>`;
// Left column: sliders
const left = html`<div style="display:grid; gap:10px; min-width:220px;"></div>`;
left.append(viewof z1, viewof z2, viewof z3, viewof z4);
// Right column: table
const rows = labels.map((cls, i) => ({
Class: cls,
z: zs[i],
"exp(z)": exps[i],
Probability: ps[i]
}));
const right = html`<div style="
min-width:240px;
max-width:660px;
padding:4px 0;
font-size:2.00rem;
line-height:1.1;
"></div>`;
right.append(
Inputs.table(rows, {
columns: ["Class", "z", "exp(z)", "Probability"],
format: {
z: d => d.toFixed(2),
"exp(z)": d => d.toFixed(3),
Probability: d => (d * 100).toFixed(1) + "%"
}
})
);
container.append(left, right);
return container;
}Plot.plot({
width: 900, // wider
height: 120, // taller
marginLeft: 20,
marginRight: 20,
marginBottom: 50,
x: {
domain: [0, 1],
tickFormat: d => (d * 100).toFixed(0) + "%",
label: "Probability",
labelArrow: false,
labelAnchor: "center",
tickSize: 10,
tickPadding: 8
},
y: { axis: null },
// Bigger fonts everywhere
style: {
fontSize: "18px", // main text size
fontFamily: "sans-serif"
},
color: {
legend: true,
label: "Class",
tickSize: 12
},
marks: [
Plot.barX(
data,
Plot.stackX({ x: "value", y: "row", fill: "label", sort: { fill: null } })
),
Plot.ruleX([0, 1])
]
})