Hierarchical Models
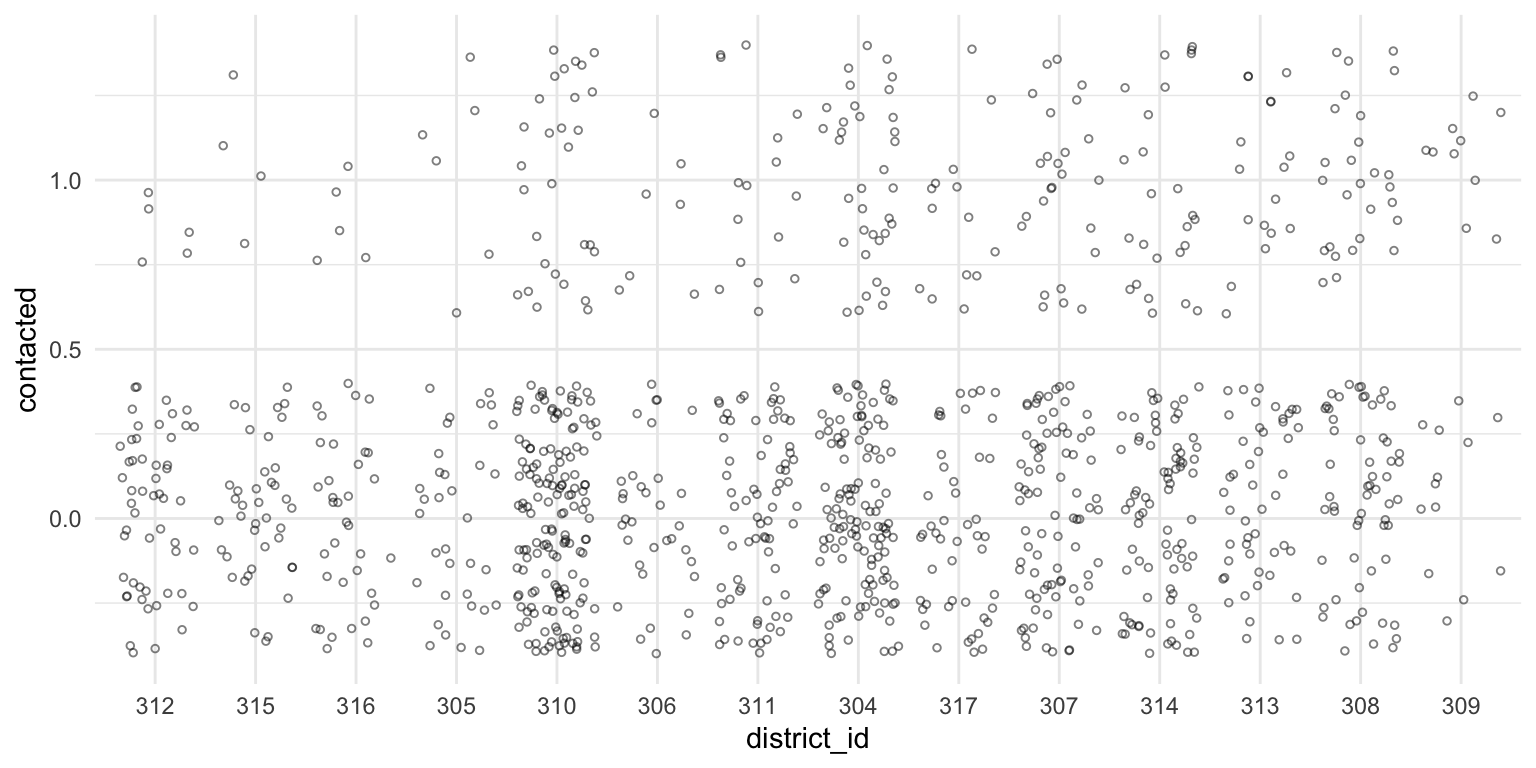
Always scatterplot your data
A scatterplot is a safe and potentially informative way to start.
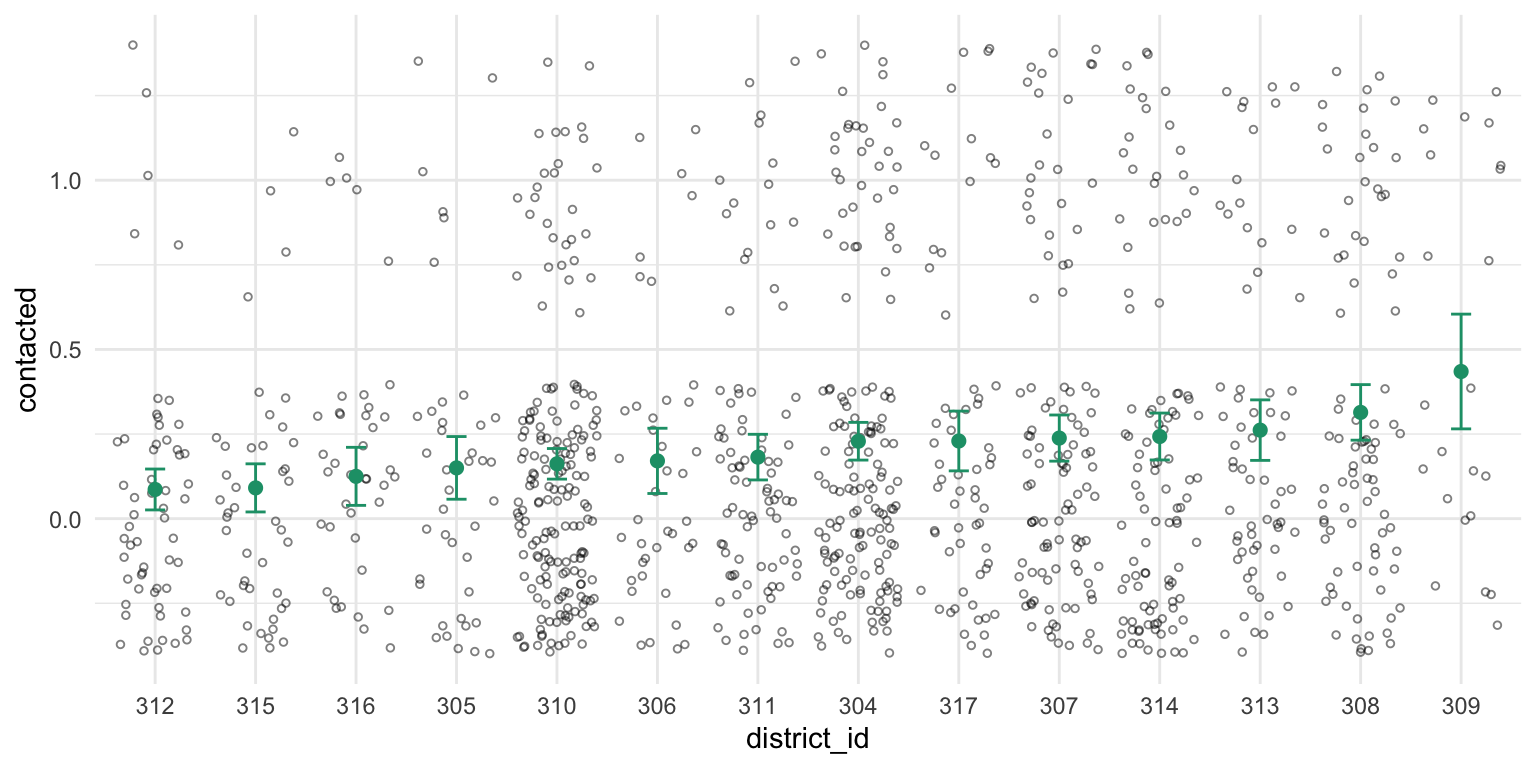
Adding the estimates to the scatterplot
Now let’s add these estimates to the scatterplot.
Adding the sample size
You can see that the confidence intervals (and sample size) varies by district, so let’s add that information to the plot.
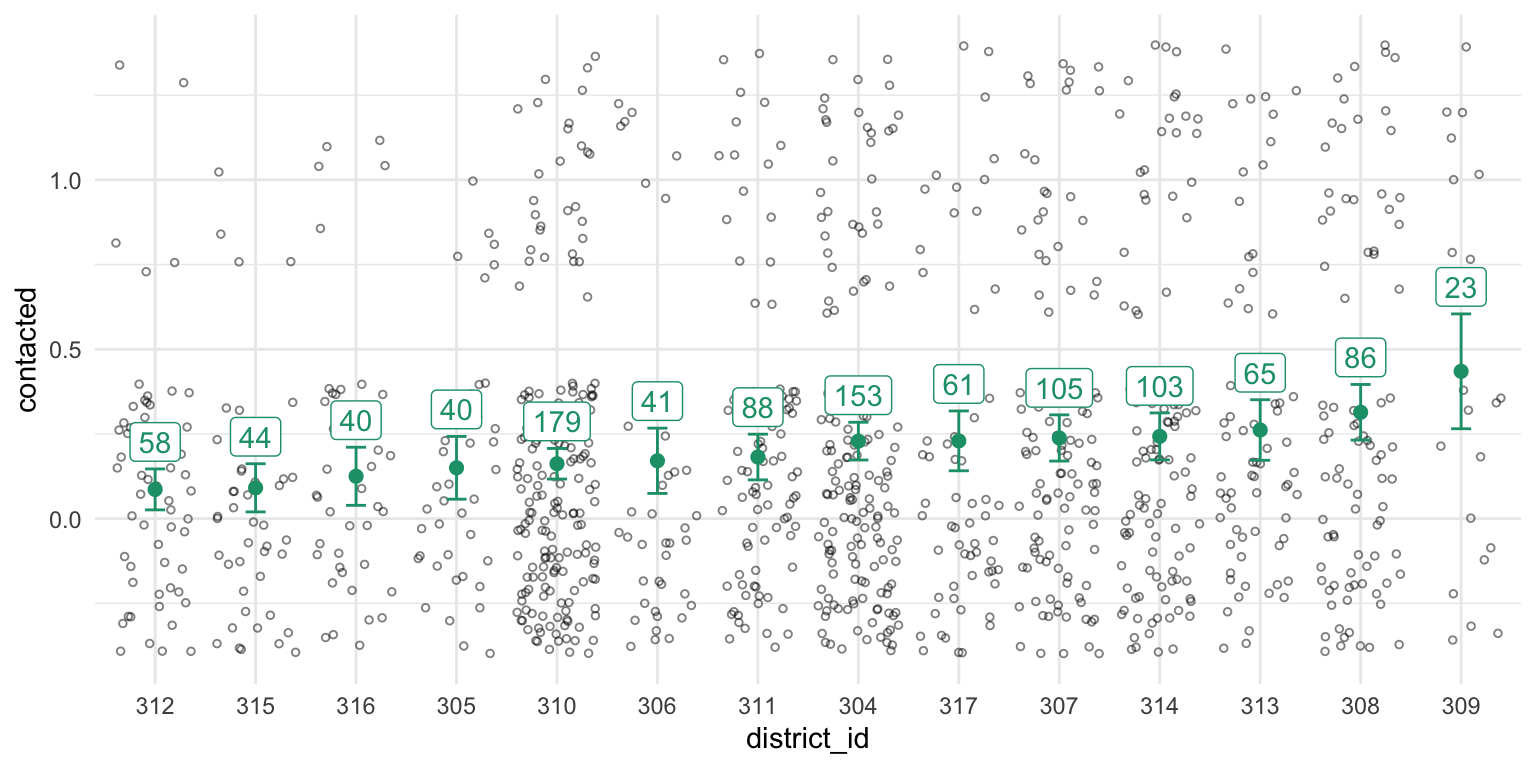
Great! Now we’re done. We’ve got ML estimates of the contact rate for all districts.
But wait… can we do better?
Looking carefully at 309
Let’s look at district 309 on the far right. We our estimate of the contact rate in this district is the highest.

Our estimator \(\hat\pi\) is unbiased, but if you had to say, would you say that the turnout rate in district 309 was higher or lower than \(\hat{\pi}_{309} = 0.40\)?
If your intuition matches mine, you will say lower. Why? This “why?” is an important question.
Comparing the ML and hierarchical estimates
We can add this to our plot to see how the estimates changed.

A plot of the partial pooling
We can compare the initial ML estimates to the hierarchical model estimates.
Code
Rows: 28
Columns: 5
$ type <chr> "initial ML", "initial ML", "initial ML", "initial ML", "initial ML"…
$ district_id <fct> 312, 315, 316, 305, 310, 306, 311, 304, 317, 307, 314, 313, 308, 309…
$ pi_hat <dbl> 0.0862, 0.0909, 0.1250, 0.1500, 0.1620, 0.1707, 0.1818, 0.2288, 0.22…
$ n <int> 58, 44, 40, 40, 179, 41, 88, 153, 61, 105, 103, 65, 86, 23, NA, NA, …
$ se_hat <dbl> 0.0369, 0.0433, 0.0523, 0.0565, 0.0275, 0.0588, 0.0411, 0.0340, 0.05…
We did not implement complete pooling above, but we can do it here to compare the three approaches.
Code
# use the overall rate for each district
common_estimate <- tibble(district_id = unique(finland$district_id)) %>%
mutate(pi_hat = mean(finland$contacted))
# combine the three types
comb <- bind_rows(list("No Pooling" = estimates,
"Partial Pooling" = hier_estimates,
"Complete Pooling" = common_estimate),
.id = "type") %>%
mutate(type = reorder(type, pi_hat, var))
gg_comb2 <- ggplot(comb, aes(x = pi_hat, y = type)) +
geom_point(alpha = 0.5) +
geom_line(aes(group = district_id), alpha = 0.5)
print(gg_comb2) 
Key things
First, the 309 problem.
Second, \(\mu_i = \alpha_{j[i]} + \beta x_i\), where \(\alpha_j \sim N(0, \sigma^2_\alpha)\).
Third, the figure below.








